
Скрапинг — это автоматический сбор данных с веб-страниц: программа-скрапер отправляет HTTP-запрос, получает HTML и вытаскивает из него нужные фрагменты — цены, тексты, ссылки, контакты. Там, где вручную вы скопировали бы десять страниц, скрапинг обрабатывает тысячи за минуты. На Python его собирают из связки Requests + BeautifulSoup, а для сложных сайтов берут Scrapy или Playwright.
Коротко, что важно знать до старта:
- Скрапинг = «скачать страницу», парсинг = «разобрать её на данные»; на практике это два шага одного конвейера.
- Простой статичный сайт закрывается связкой Requests + BeautifulSoup за десяток строк.
- Динамический контент на JavaScript обычными запросами не берётся — нужен Playwright или Selenium.
- Правовая сторона реальна: персональные данные, robots.txt и условия использования сайта игнорировать нельзя.
- Готовые no-code сервисы решают задачу без единой строки кода, но с потолком по гибкости.
Материал редакции Зерокодера, обновлено в 2026 году. Разбираем на рабочем примере — скрапе каталога Литрес, который прогоняли сами.
Что такое скрапинг?
Скрапинг сайтов — это процесс извлечения информации со страниц. В основе лежит анализ HTML-кода страницы и вытягивание из него нужных данных. Например, можно собрать карточки товаров из интернет-магазина, выгрузить новости с агрегатора или снять статистику для анализа.
Часто скрапинг путают с парсингом и краулингом, хотя это разные операции одного конвейера. Краулер обходит сайт по ссылкам и составляет список адресов, скрапер загружает содержимое найденных страниц, а парсер разбирает загруженный HTML на структурированные поля. По классификации Википедии, техник скрапинга насчитывают до семи — от простого копирования и регулярных выражений до DOM-анализа и распознавания через компьютерное зрение.
| Операция | Что делает |
| Краулинг | Находит страницы, обходит сайт по ссылкам |
| Скрапинг | Загружает содержимое найденных страниц |
| Парсинг | Извлекает из HTML конкретные поля и структурирует их |

- ПОКАЖЕМ, КАК РАЗВЕРНУТЬ МОДЕЛЬ нейросети DEEPSEEK R1 ПРЯМО НА СВОЁМ КОМПЬЮТЕРЕ
- Где и как применять? Потестируем модель после установки на разных задачах
- Как дообучить модель под себя?
Как работает скрапинг?
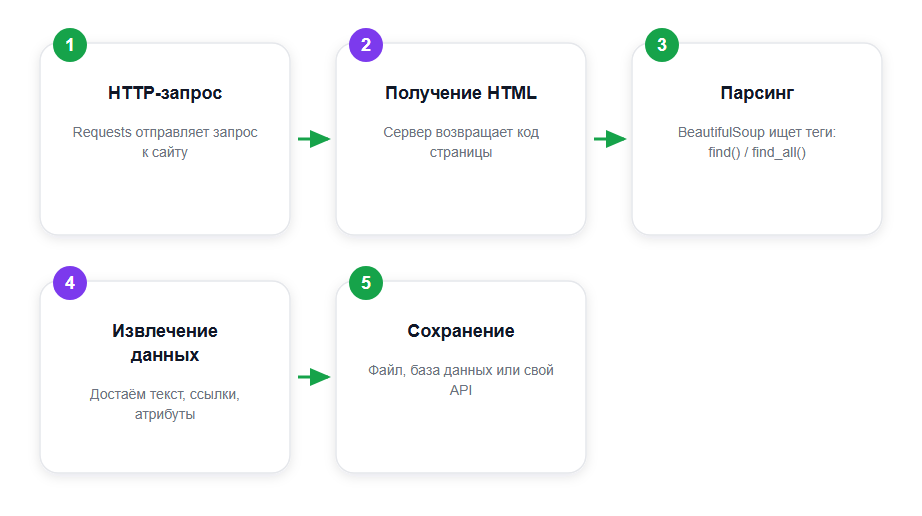
Процесс начинается с отправки HTTP-запроса к сайту, чтобы получить HTML-код страницы. Затем этот код анализируется парсером, который извлекает нужные данные. Python предлагает несколько библиотек — включая BeautifulSoup и Scrapy, — которые сильно упрощают работу. В общем виде путь данных выглядит так: запрос отправлен, HTML получен, разобран, нужные поля извлечены и сохранены в файл или базу.
Зачем нужен скрапинг: где его применяют
Скрапинг — не абстрактный навык, а рабочий инструмент в нескольких сферах:
- E-commerce и мониторинг цен. Магазины снимают цены и ассортимент конкурентов, чтобы держать прайс актуальным.
- Лидогенерация. Сбор открытых контактов и карточек компаний для отделов продаж.
- Обучение ИИ-моделей. Датасеты для машинного обучения нередко собирают именно скрапингом открытых страниц.
- Аналитика и SEO. Сбор выдачи, отзывов, новостей для конкурентной разведки.
- Наполнение каталогов и агрегаторов. Автоматический перенос данных из источников в свою витрину.
Инструменты для скрапинга на Python: что под какую задачу
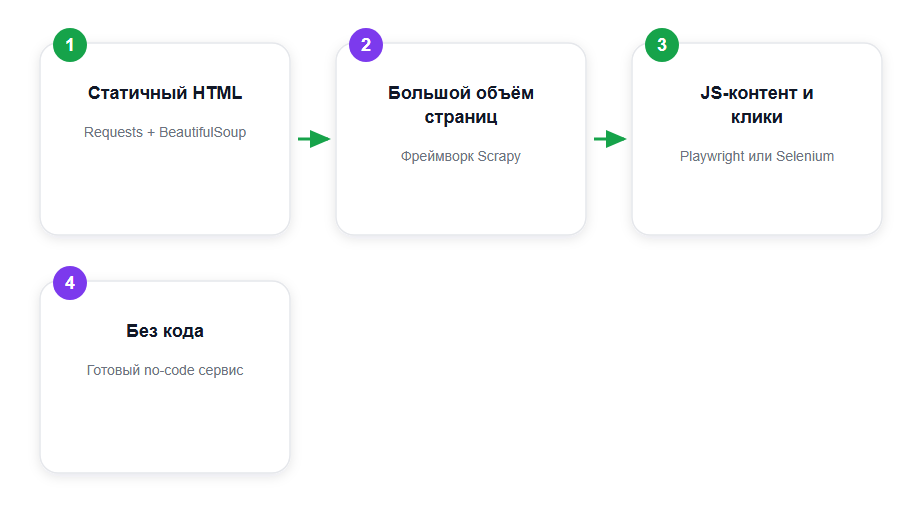
Python — популярный язык для скрапинга сайтов, и выбор инструмента зависит не от моды, а от типа сайта. Ниже — карта, которая экономит время на старте.
| Инструмент | Что делает | Когда брать | Порог входа |
| Requests | Отправляет HTTP-запросы, получает HTML | Основа любого скрапера статичных сайтов | Низкий |
| BeautifulSoup | Парсит HTML/XML, ищет элементы по тегам и классам | Простые статичные страницы | Низкий |
| Scrapy | Полноценный фреймворк со встроенными пауками и экспортом | Много страниц, масштаб, регулярные выгрузки | Средний |
| Selenium | Управляет реальным браузером, кликает и заполняет формы | Динамический контент, авторизация | Средний |
| Playwright | Современный движок браузера, ждёт AJAX-запросы | Тяжёлые JS-сайты и SPA | Средний |
| No-code сервисы | Визуальный сбор без кода | Разовые задачи без программирования | Минимальный |
Правило простое: статичный HTML — Requests + BeautifulSoup; большой объём — Scrapy; контент подгружается скриптами и требует кликов — Selenium или Playwright. Если у сайта тяжёлый JavaScript, обычные запросы вернут пустую разметку, и без браузерного движка не обойтись. Подробный старт с браузерной автоматизацией мы разбирали в материале «Знакомство с Selenium», а промышленную выгрузку — в цикле про настройку проекта на Scrapy.
Процесс скрапинга сайтов: пошагово
Разберём общий процесс скрапинга на Python и BeautifulSoup:
- Отправка HTTP-запроса. Сначала отправляем запрос к сайту, чтобы получить HTML-код страницы. Для этого используем библиотеку Requests.
- Получение HTML-кода. В ответ приходит HTML-код страницы — сохраняем его в переменную для дальнейшего анализа.
- Парсинг HTML-кода. Применяем методы поиска
find()иfind_all(), чтобы найти теги и атрибуты с нужными данными. Эти методы описаны в официальной документации BeautifulSoup. - Извлечение данных. После нахождения элементов достаём из них содержимое. Например, метод
get_text()вернёт текст заголовка. - Обработка данных. Готовые данные сохраняем в файл, кладём в базу, отдаём в анализ или в собственный API.
Пример кода
Вот рабочий скрипт на Python, который демонстрирует базовый процесс скрапинга с помощью BeautifulSoup. Мы отправляем запрос на Литрес и собираем список книг с автором, названием и ссылкой:
| # Подключение библиотек
import requests from bs4 import BeautifulSoup # Отправляем запрос и получаем текст страницы link = ‘https://www.litres.ru/genre/dom-dacha-201647/’ result = requests.get(link) # Разбираем HTML в объект BeautifulSoup soup = BeautifulSoup(result.text, ‘html.parser’) # Находим все карточки книг на странице books = soup.find_all(‘div’, class_=’art-item’) # Список для результатов — каждый элемент = одна книга list_books = [] # В цикле обрабатываем найденные карточки for item in books: dict_book = { ‘author’: item.find(‘a’, class_=’author_name-no_js’).get_text(strip=True), ‘title’: item.find(‘a’, class_=’bookname descr-no_js’).get_text(strip=True), ‘url’: ‘https://www.litres.ru’ + item.find(‘a’).get(‘href’), } list_books.append(dict_book) |
Отличие от старой версии скрипта — здесь HTML сначала разбирается в объект soup, а список books реально заполняется через find_all(). Без этого шага цикл не по чему итерировать. По этой же логике на связке ChatGPT и Python мы собирали скрапер для Airbnb — принцип тот же, меняются только селекторы.
Если вы только заходите в тему и хотите собрать первый рабочий скрапер под руководством наставника, это удобно сделать на курсе по веб-разработке Зерокодера.
Что мешает скрапингу и как сайты защищаются
На боевых сайтах простой скрипт часто спотыкается. Основные препятствия:
- Динамический контент. Данные подгружаются JavaScript после загрузки страницы — в исходном HTML их нет. Решение — браузерные движки Playwright или Selenium.
- Ограничение частоты запросов (rate limit). Слишком частые обращения с одного адреса блокируются. Помогает пауза между запросами и уважение к нагрузке сайта.
- Капча. Проверка «человек или бот» останавливает автоматический сбор.
- Блокировка по IP и фингерпринтинг. Сайт вычисляет бота по отпечатку соединения; на этот случай используют прокси и ротацию заголовков.
Общий принцип — вести себя как аккуратный посетитель, а не как DDoS: разумный темп запросов сохраняет и доступ, и репутацию.
Правовые аспекты скрапинга
Скрапинг открытых данных сам по себе законен, но у него есть рамки, и их стоит знать до запуска.
- Персональные данные. В России их обработку регулирует Федеральный закон №152-ФЗ «О персональных данных». Сбор ФИО, телефонов и почт без основания — зона риска.
- robots.txt и условия использования. Многие сайты в правилах запрещают автоматический сбор. Перед запуском прочитайте пользовательское соглашение и файл robots.txt — как это делать программно, мы показывали в разборе robots.txt и sitemap.xml на Python.
- Международный контекст. В ЕС действует регламент GDPR, а в США известен прецедент hiQ Labs против LinkedIn: суд признал, что скрапинг общедоступных данных не нарушает закон о компьютерном мошенничестве. Детали — в статье Википедии о веб-скрейпинге.
- Нагрузка. Не заваливайте сайт запросами — это не только этично, но и снижает риск блокировки и претензий.
Частые вопросы о скрапинге
Скрапинг — это законно?
Сбор общедоступных данных законен, если вы не нарушаете правила сайта и законодательство о персональных данных (в России — 152-ФЗ). Сбор личных данных или обход защиты — уже зона риска.
Чем скрапинг отличается от парсинга?
Скрапинг — это загрузка страницы, парсинг — разбор загруженного HTML на конкретные поля. На практике это два соседних шага одного процесса.
Какой инструмент выбрать новичку?
Для простых статичных сайтов начните со связки Requests + BeautifulSoup: это минимальный порог входа. Для динамических сайтов переходите на Playwright или Selenium, для масштаба — на Scrapy.
Можно ли скрапить сайты без программирования?
Да, для разовых задач подойдут no-code сервисы с визуальным сбором данных. Но по гибкости и объёму они уступают собственному скрипту на Python.
Заключение
Скрапинг веб-сайтов — это инструмент сбора данных из интернета, который на Python реализуется быстро: Requests тянет страницу, BeautifulSoup разбирает её, Scrapy и Playwright закрывают масштаб и динамику. Главное — выбирать инструмент под тип сайта и держать в голове правовые рамки. Тогда скрапинг превращается из разовой хитрости в надёжный источник актуальных данных.
- Освой нейросеть Perplexity и узнай, как пользоваться функционалом остальных ИИ в одном
- УЧАСТВОВАТЬ ЗА 0 РУБ.
- Расскажем, как получить подписку
- ПОКАЖЕМ, КАК РАЗВЕРНУТЬ МОДЕЛЬ нейросеть DEEPSEEK R1 ПРЯМО НА СВОЁМ КОМПЬЮТЕРЕ


