
Коротко о главном:
- Qwen3-TTS — открытая модель синтеза речи нового поколения от Qwen.
- Поддерживает клонирование голоса за 3 секунды, дизайн уникального тембра и тонкую настройку эмоций.
- Работает на 10 языках, включая русский.
- Генерирует звук с задержкой всего ~97 мс — подходит для стриминга и реального времени.
- Доступна в open-source на GitHub и через Qwen API.
Если раньше голос, сгенерированный ИИ, звучал как автоответчик из 2007 года, то теперь синтез речи почти не отличить от живого человека.
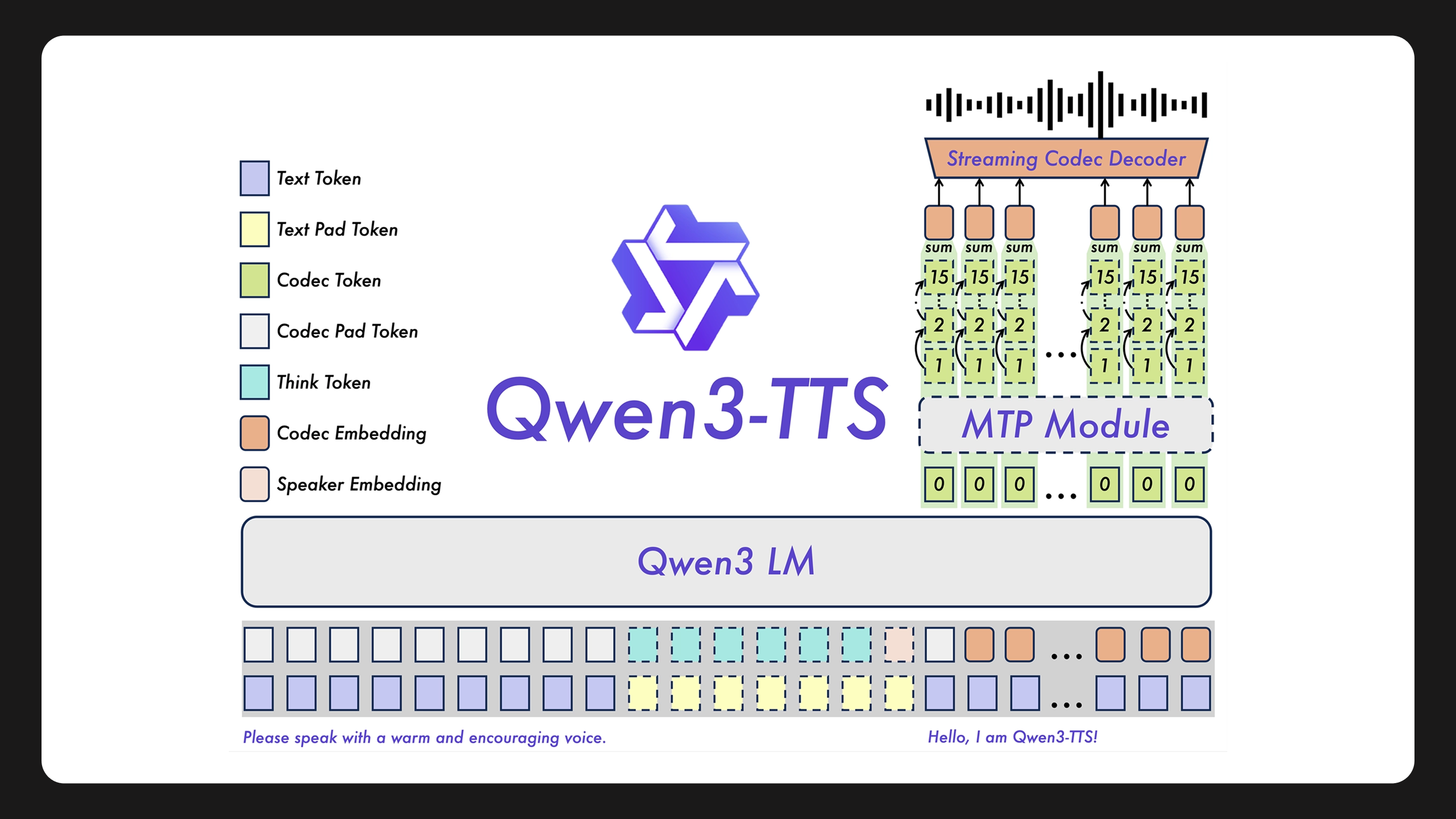
Что такое Qwen3-TTS
TTS (Text-to-Speech) — это технология, которая превращает текст в речь. А Qwen3-TTS — это целая экосистема:
- дизайн нового голоса по описанию,
- клонирование существующего,
- управление эмоциями,
- генерация диалогов между персонажами,
- поддержка разных языков и диалектов.
Главная фишка — голос можно описать словами, как будто вы ставите задачу актёру озвучки. Например: «Мужской голос, 30 лет, спокойный, чуть ироничный, говорит быстро, но чётко».
Модель это понимает и воспроизводит.
Из-за чего голос звучит естественно
Секрет в собственном аудиотокенизаторе Qwen3-TTS-Tokenizer-12Hz.
Если объяснять просто: обычные системы разбивают звук грубо — как если бы вы сжимали фото до пиксельной каши. Здесь же используется multi-codebook подход, который сохраняет интонации, дыхание, микропаузы и эмоциональные оттенки.
По тестам на LibriSpeech:
- PESQ до 3.68 (высокая субъективная чёткость),
- STOI 0.96 (почти идеальная разборчивость),
- speaker similarity 0.95 (голос сохраняется почти без потерь).
Для обычного пользователя это означает одно: голос звучит живым, а не искусственным.
Расскажем больше о топовых китайских нейросетях, работающих в России без VPN, на бесплатном онлайн-практикуме!

- ПОКАЖЕМ, КАК РАЗВЕРНУТЬ МОДЕЛЬ нейросети DEEPSEEK R1 ПРЯМО НА СВОЁМ КОМПЬЮТЕРЕ
- Где и как применять? Потестируем модель после установки на разных задачах
- Как дообучить модель под себя?
Что вы можете делать с Qwen3-TTS
1. Клонировать голос
Нужно всего около 3 секунд аудио.
Представьте:
- Вы блогер и хотите озвучивать статьи автоматически.
- Вы делаете образовательный курс.
- Вы создаёте игрового персонажа.
Модель воспроизводит тембр, а дальше вы управляете стилем через текстовые инструкции.
Причём работает даже кросс-языковое клонирование. Русский голос может говорить на английском, сохраняя индивидуальность.
2. Создать голос с нуля
Можно описать голос как персонажа: «Женщина 45 лет, низкий спокойный тембр, ощущение уверенности и лёгкой усталости».
Модель создаёт новый тембр. Это полезно для подкастов, аудиокниг, корпоративных голосовых ассистентов или игровых NPC.
3. Управлять эмоциями
Вы можете задать злость, иронию, шёпот, ускорение речи, постепенное нарастание громкости. Причём управление может быть динамическим — в начале спокойно, в конце эмоционально.
Это уже не просто TTS, а почти цифровой актёр.
4. Делать диалоги между персонажами
Можно сохранить несколько тембров и использовать их в длинных диалогах.
Подходит для сторителлинга, анимации, обучающих симуляторов и роликов для соцсетей.
Сколько времени занимает генерация
Qwen3-TTS использует Dual-Track архитектуру.
Первый аудиофрагмент появляется после обработки одного символа текста. Задержка — около 97 миллисекунд. Это означает, что можно строить голосовые ассистенты, стриминговые боты и real-time переводчики.
Для сравнения: в 2022 году подобная скорость считалась почти недостижимой для open-source решений.
Две версии модели: какую выбрать
Есть две основные конфигурации:
- 1.7B — максимальное качество и контроль.
- 0.6B — баланс между скоростью и производительностью.
Если вы:
- разрабатываете продукт — берите 1.7B,
- экспериментируете или ограничены ресурсами — 0.6B будет достаточно.
Поддержка языков
Модель работает на:
- русском,
- английском,
- китайском,
- японском,
- корейском,
- немецком,
- французском,
- португальском,
- испанском,
- итальянском.
Для российского рынка это особенно важно: русский язык поддерживается полноценно, включая сложные слова и даже текст с шумом и символами.
Как попробовать Qwen3-TTS: простой гайд
Способ 1. Через GitHub
- Перейдите на официальный репозиторий Qwen3-TTS на GitHub.
- Скачайте модель.
- Установите зависимости (обычно через pip).
- Запустите пример скрипта генерации.
Это подойдёт, если вы знакомы с Python.
Способ 2. Через Qwen API
- Зарегистрируйтесь в Alibaba Cloud Model Studio.
- Создайте API-ключ.
- Подключитесь к модели через совместимый OpenAI API формат.
Дальше вы отправляете текст и получаете аудиофайл в ответ. Для новичков это самый простой путь.
Где это можно применить в России
- Озвучка Telegram-каналов.
- Автоматическая генерация подкастов.
- Голосовые помощники для бизнеса.
- Локализация контента.
- Онлайн-образование.
- Диджитал-аватары для маркетинга.
Потребление подкастов в России продолжает расти, а автоматизация озвучки снижает расходы в 5–10 раз по сравнению с живой студийной записью.
Чем Qwen3-TTS отличается от других решений
Если сравнивать с закрытыми сервисами вроде ElevenLabs, Qwen3-TTS выигрывает в открытости и гибкости.
Если сравнивать с open-source альтернативами, то у Qwen3-TTS выше качество реконструкции, ниже задержка, лучше управление эмоциями и сильнее кросс-языковое клонирование.
По тестам модель обошла MiniMax и SeedTTS по стабильности и точности клонирования.
Итог
Qwen3-TTS — это не просто ещё один инструмент озвучки. Это шаг к тому, чтобы голос стал программируемым интерфейсом.
Вы можете создавать цифровых персонажей, автоматизировать контент, строить голосовые продукты, экспериментировать с форматом общения. И самое интересное — всё это уже доступно в open-source.
- Выполним базовые задачи на российских нейросетях и посмотрим на результаты!
- Файл-инструкцию «Как сделать нейро-фотосессию из своего фото бесплатно, без иностранных карт и прочих сложностей»
- Покажем 10+ способов улучшить свою жизнь с ИИ каждому — от ребенка и пенсионера до управленца и предпринимателя
- Возможность получить Доступ в Нейроклуб на целый месяц
- Как ИИ ускоряет работу и приносит деньги
- За 2 часа вы получите четкий план, как начать работать с ИИ прямо сейчас!


