
Коротко о главном:
- GigaChat научился понимать речь напрямую, без промежуточного распознавания текста
- Голосовой режим уже доступен в веб-версии и Telegram
- Модель слышит интонации, эмоции и контекст, а не только слова
- Качество диалогов сравнимо с GPT-4o, без деградации текстовых возможностей
Что вообще произошло — и почему это важно
Если упростить, GigaChat перестал «переводить голос в текст, а потом думать». Теперь он сначала слышит, а уже потом понимает.
Раньше голосовые сценарии почти у всех ИИ работали одинаково: человек говорит → система распознаёт речь → текст отправляется в языковую модель → модель отвечает. Эта схема удобная, но у неё есть фундаментальный изъян — слишком много теряется по дороге.
В конце прошлого года команда GigaChat впервые показала альтернативу: нативную аудиомодальность, где речь обрабатывается целиком, как сигнал, а не как набор слов. Теперь эта технология стала доступна всем пользователям — в веб-интерфейсе giga.chat и в Telegram-боте.
И это не просто «ещё один голосовой режим». Это смена подхода. Узнать больше о новых обновлениях российских нейросетей можно на бесплатном открытом уроке!

- ПОКАЖЕМ, КАК РАЗВЕРНУТЬ МОДЕЛЬ нейросети DEEPSEEK R1 ПРЯМО НА СВОЁМ КОМПЬЮТЕРЕ
- Где и как применять? Потестируем модель после установки на разных задачах
- Как дообучить модель под себя?
Почему классическая схема ASR + LLM перестала устраивать
На бумаге связка «распознавание речи + языковая модель» выглядит логично. На практике она регулярно ломается в самых интересных местах.
Во-первых, ошибки распознавания. Сложные термины, иностранные слова, имена собственные — всё это легко превращается в кашу. Запрос вроде «чем Tensor Parallelism отличается от Sequence Parallelism» может быть искажен ещё до того, как ИИ начнёт думать над ответом.
Во-вторых, потеря эмоций и интонации. Когда вы говорите «серьёзно?» с иронией, текст этого не передаёт. А голос — передаёт. В старой схеме эта информация просто выбрасывалась.
В-третьих, длинные записи. Часовые лекции, интервью, созвоны приходилось резать на куски. Контекст рвался, смысл расползался, а итоговая суммаризация выглядела так, будто её писал человек, который слушал в пол-уха.
И наконец, языки. GigaChat знает больше языков, чем отдельные ASR-модели. Но связка ограничивалась самым слабым звеном.
Все эти ограничения подтолкнули команду к логичному, но сложному шагу: научить модель воспринимать речь напрямую.
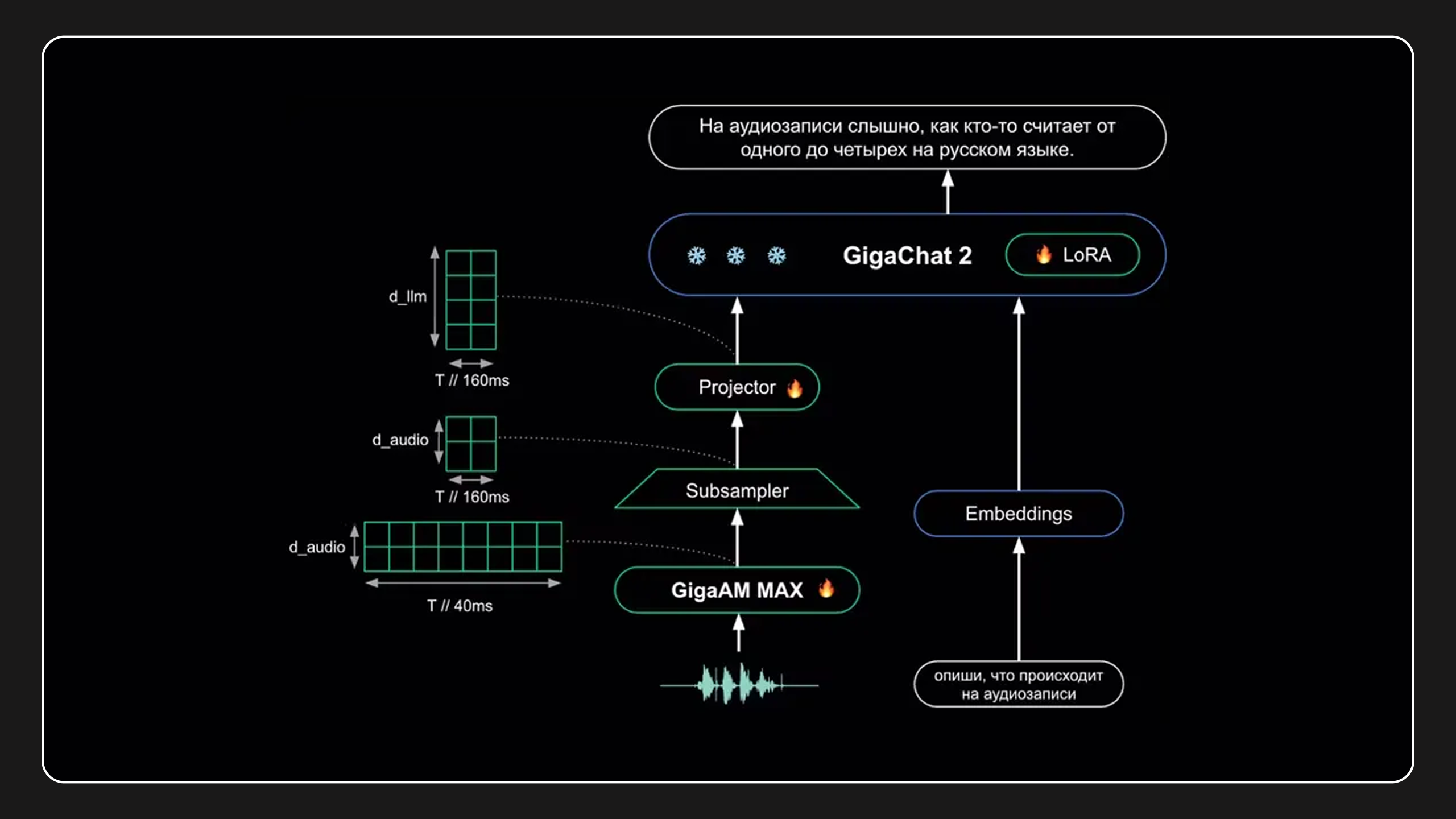
Как устроена аудиомодальность GigaChat — без формул и перегруза
Если представить GigaChat как мозг, то аудиомодальность — это полноценный слух, а не диктофон с автотранскрипцией.
Сначала аудиосигнал попадает в специализированный аудиоэнкодер. Он обучен находить в звуке не только слова, но и паузы, темп, акценты, эмоциональные маркеры. Это похоже на то, как человек понимает собеседника ещё до того, как осознал каждую фразу.
Дальше работает адаптационный слой, который «переводит» аудиопредставления на язык, понятный GigaChat. Причём сделано это максимально экономно по контексту — модель умеет сжимать длинные записи без потери смысла.
И уже затем подключается сам GigaChat 2 Max, слегка дообученный под работу с аудио. Важно: основная языковая модель не переписывалась с нуля, поэтому её текстовые способности не пострадали.
Результат — единая end-to-end система, где нет разрыва между «услышать» и «понять».
На чём обучали модель и почему это имеет значение
Аудиомодель не появляется из воздуха. Чтобы она начала «чувствовать» речь, её прогнали через сотни тысяч часов аудио — от чистых студийных записей до шумных разговоров, диалогов, лекций и живых сцен.
Особый упор сделали не на сухое распознавание, а на реальные сценарии:
- диалоги с перебиваниями
- длинные записи для суммаризации
- запросы с эмоциями, сомнениями, иронией
- голосовые команды для вызова функций
Интересный момент — активное использование синтетических данных. Тексты озвучивались с помощью технологий синтеза речи, что позволило быстро масштабировать обучение без бесконечных студийных записей. Это редкий случай, когда «синтетика» реально улучшает качество, а не портит его.
Как модель справляется с длинным аудио
Одна из самых сложных задач — работа с часовыми записями. Тут стандартные архитектуры просто захлёбываются: не хватает памяти, контекст разваливается, ответы становятся поверхностными.
В GigaChat пошли другим путём. Архитектуру аудиоэнкодера упростили там, где это мешало масштабированию, а обучение перестроили так, чтобы модель регулярно видела длинные записи, а не сталкивалась с ними впервые на продакшене.
В результате GigaChat спокойно:
- делает выжимки из длинных интервью
- отвечает на вопросы по лекциям и подкастам
- удерживает общий смысл даже при большом объёме аудио
Проверка качества: цифры, а не ощущения
Чтобы не полагаться на «нам кажется, стало лучше», провели масштабные сравнения.
В side-by-side тестах пользователи и AI-тренеры сравнивали ответы старой схемы (ASR + GigaChat) и новой end-to-end модели. Итог — уверенная победа аудиомодальности. Она отвечала короче, точнее и реже галлюцинировала на деталях.
Дополнительно проверили, не пострадал ли сам GigaChat как текстовая модель. Потери оказались минимальными — в пределах 3–5 %, что для добавления новой модальности считается отличным результатом.
Проще говоря: модель научилась слышать, не забыв, как думать.
Что это даёт обычному пользователю
Теперь о самом приятном — практике.
Вы можете просто нажать кнопку «Общаться голосом» и говорить, не подбирая формулировки. GigaChat понимает живую речь, позволяет перебивать себя, поддерживает диалог, а при желании отправляет аккуратную текстовую расшифровку, которой удобно делиться.
Это особенно круто работает в сценариях:
- быстрые бытовые вопросы
- обучение и репетиторство
- разбор презентаций и публичных выступлений
- суммаризация видео и подкастов
- голосовые команды вместо печати
А ещё модель умеет анализировать неречевые звуки — пусть и не идеально, но уже на удивление уверенно.
Аудио + визуал: шаг к нормальному диалогу с ИИ
Следующий уровень — объединение аудио и изображений. Теперь вы можете показать картинку и задать вопрос голосом, не переключаясь между режимами.
Важно, что аудиомодальность подключается только тогда, когда она действительно нужна. Если вы общаетесь текстом или картинками — качество не падает.
Это приближает общение с ИИ к тому, как мы общаемся друг с другом: видим, слышим и понимаем в одном контексте.
Что дальше
За год GigaChat прошёл путь от классической схемы «распознал — ответил» до полноценной end-to-end аудиомодели. По качеству диалогов она уже сравнима с GPT-4o, а в ряде русскоязычных сценариев чувствует себя даже увереннее.
Впереди — расширение языков, более глубокие аудио-визуальные сценарии и следующий логичный шаг: speech-to-speech, когда модель будет не только понимать голос, но и отвечать им нативно, с эмоциями и интонацией.
Если коротко: GigaChat больше не просто «читает, что вы сказали». Он начинает слышать вас по-настоящему.
- Выполним базовые задачи на российских нейросетях и посмотрим на результаты!
- Файл-инструкцию «Как сделать нейро-фотосессию из своего фото бесплатно, без иностранных карт и прочих сложностей»
- Покажем 10+ способов улучшить свою жизнь с ИИ каждому — от ребенка и пенсионера до управленца и предпринимателя
- Возможность получить Доступ в Нейроклуб на целый месяц
- Как ИИ ускоряет работу и приносит деньги
- За 2 часа вы получите четкий план, как начать работать с ИИ прямо сейчас!


